PDF metadata consists of information about the PDF document, which includes title of the PDF document, author, subject, keywords and copyright information. This information falls under searchable fields of a PDF document, which means that they can be accessed by search utilities.
A typical office computer contains dozens of documents and files which are accessed by its users from time to time. These documents have to be organized and stored in a way that they are easily retrievable. An ill-organized collection of documents, one that contains hundreds of digital documents, can become a nightmare to navigate through.
The problem is exacerbated for vision-impaired users, as they rely solely on assistive technology (such as screen readers) to navigate and access documents on a computer.
This is where metadata comes into play.
What is PDF metadata?
In simple words, PDF metadata is data about a PDF document. It provides additional information about a PDF document, including but not limited to, file name of the document, its title, date of creation, author, title, copyright information and what application was used to create the file. PDF metadata refers to the properties of a PDF document that identify what that PDF is all about.
What are the components of metadata?
A few attributes of a PDF document (or any digital document, for that matter) make up its metadata. Some of them are: title, author, subject, keywords and language.
You can read an in-depth explanation of these metadata components in this article: Components of PDF Metadata and Their Importance in Ensuring PDF Accessibility
How to view PDF metadata?
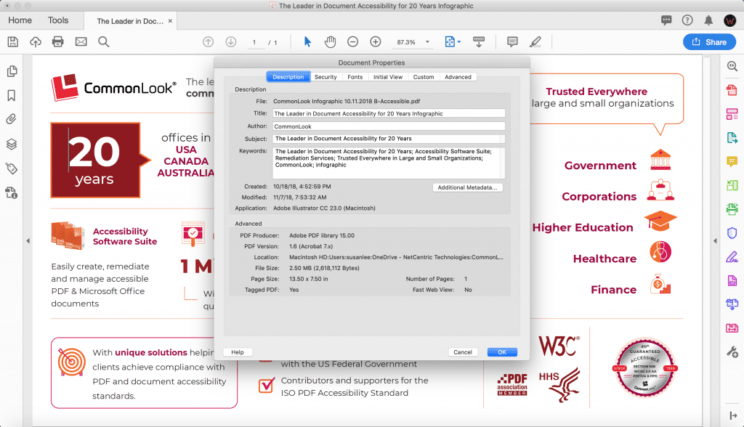
Open the concerned PDF document in Adobe Acrobat and go to File > Properties > Description.
It will show you a window that consists of different components of the metadata of the concerned PDF document.
You can also view the metadata in CommonLook PDF Validator – a free tool that not only provides detailed information about the PDF document but also tells you whether that document is accessible to compliance standards like WCAG 2.1 AA, PDF/UA and HHS Standards. This tool can act as a PDF metadata viewer.
For checking the metadata of a PDF in PDF Validator, after you open the document in PDF Validator, in the ribbon on the Windows tab, click the third button from the left to open the Metadata panel at the lower right side of the user interface. Or, use the Active Tools Window pane, and your arrow keys, to get to the Metadata panel.

How to edit PDF Metadata?
There are massive amounts of PDF documents – hosted on websites and other digital assets of organizations all over the world – whose metadata is not optimized. Not only it creates a problem from an accessibility standpoint, but it also makes those organizations liable to accessibility lawsuits. This is why it’s crucial to edit and optimize metadata of PDF documents.
CommonLook PDF – a plugin that works within Adobe Acrobat – lets you do just that.
It will prompt you to address all metadata concerns. Like Acrobat, your document will receive a Failure grade if you neglect the add or display the Title or if the language is not set. Fortunately, the Fix Wizard in CommonLook PDF makes these things a breeze to correct!
Though Acrobat will give you a Pass if the document has those settings correct, CommonLook will ask you to go one step further and verify their accuracy. If you notice a mistake, CommonLook makes it easy to add or edit all of the metadata, including the Subject, Author and Keywords.
Why is PDF metadata important: 3 things you should know about
Better identification and accessibility
Since metadata comprises vital information about a particular PDF document, it is quite valuable since it helps you determine what a PDF document is all about.
Here’s an example: say, you do a quick search for the keyword “what is an accessible PDF?” When you press Enter, Google will show you a list of results distributed over many pages. Each search result, if you notice, contains a snippet of some information about its target website. You most likely see a title, a URL and a short description of the target website right there in Google search results.
Imagine what would it be like if instead of such detailed search results, you could only see the name of the target website. Pretty inconvenient, right?
This is exactly what PDF metadata does for a PDF document. It attaches additional information about the file which is vital for its identification and accessibility.
PDF metadata comes in handy when you classify documents in the Document Management System of your organization. A PDF file that has its metadata in order can be easily looked up (and accessed) by any user; all they need to do is search for PDF documents with a specific set of keywords, author name or creation date.
Compliance to accessibility standards
Metadata of a PDF document not only ensures that it is easily identifiable, but it’s a requirement for certain accessibility standards. Accessibility requirements mandate that PDF Titles need to be displayed when the document is opened, as opposed to the File Name.
For instance, if your organization needs to make your PDFs conform with the HHS standard (U.S. Dept. of Health and Human Services) there are other requirements regarding the Title, specifically the types of characters that are (or are not) allowed. For more details, check out the Role of Metadata in PDF Accessibility.
Better visibility in search engines (like Google and Bing)
PDF documents pop up quite frequently in search engine results. As such, if your organization’s PDF documents pop up in search engine results, they will have a good chance of being discovered and clicked upon if they have appropriate metadata.
